This page has been visited 5957 times.
| Distributed User Location Design |
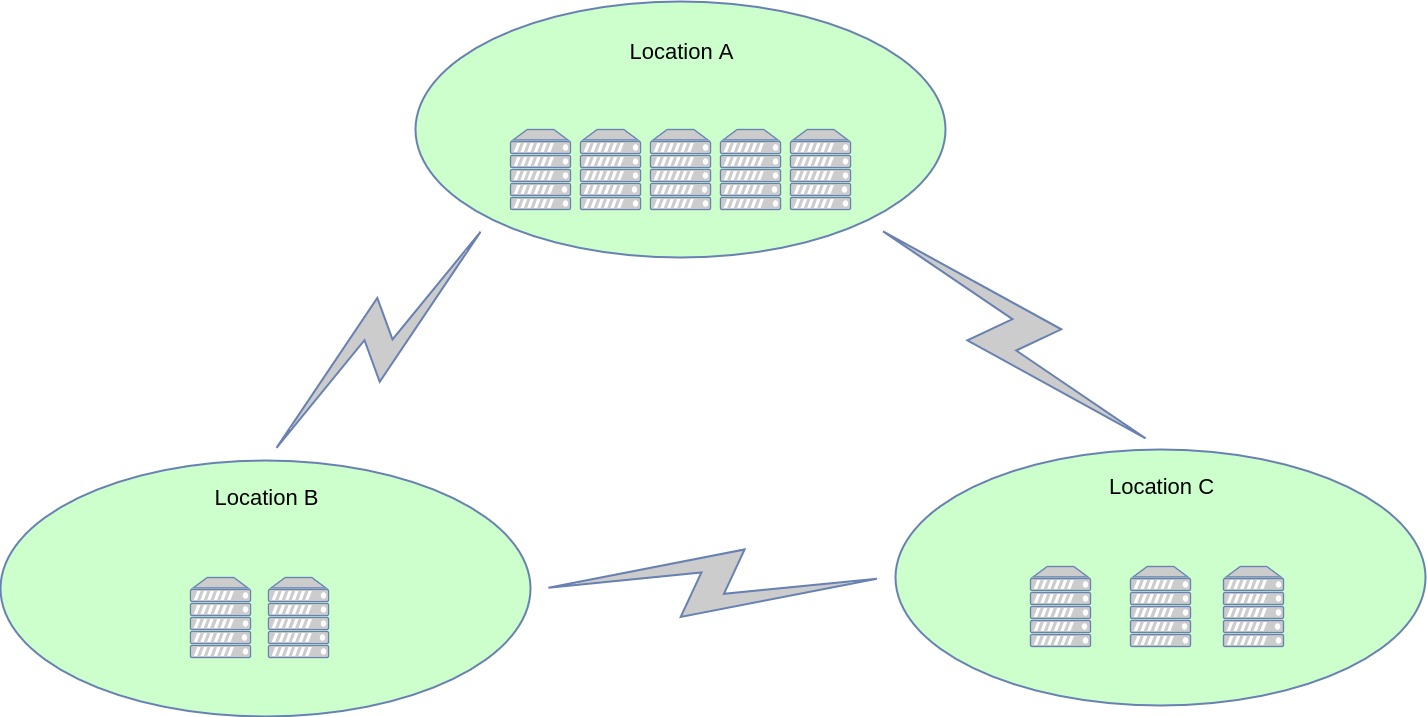
This page aims at offering high-level information regarding the development of several distributed user location models which are to be included in the OpenSIPS 2.4 release. By putting together several community discussions (2013 "users" mailing list, 2015 public meeting) along with our own experience with regards to this topic, we present two models which simultaneously address needs such as horizontal scalability, geo distribution, high availability and NAT traversal.
1. "User facing" topology
Below is a set of features specific to this model:
- geographically distributed - the overall platform may span across several physical locations, with any of its users being reachable from any of these locations.
- NAT traversal - with regards to the above, calls to a given user are properly routed out through the user's "home box" (the box it registered with)
- NAT pinging - no extraneous pinging; only the "home box" of a user is responsible for pinging the user's device
- horizontally scalable - locations may be scaled according to needs, by adding additional OpenSIPS cluster nodes and balancing traffic to them (DNS SRV, SIP load balancers, UA policies, etc.)
- highly available - optional support for pairing up any of the nodes with a "hot backup" box
We present two solutions for achieving this setup: a "SIP driven" solution and a "cluster driven" one.
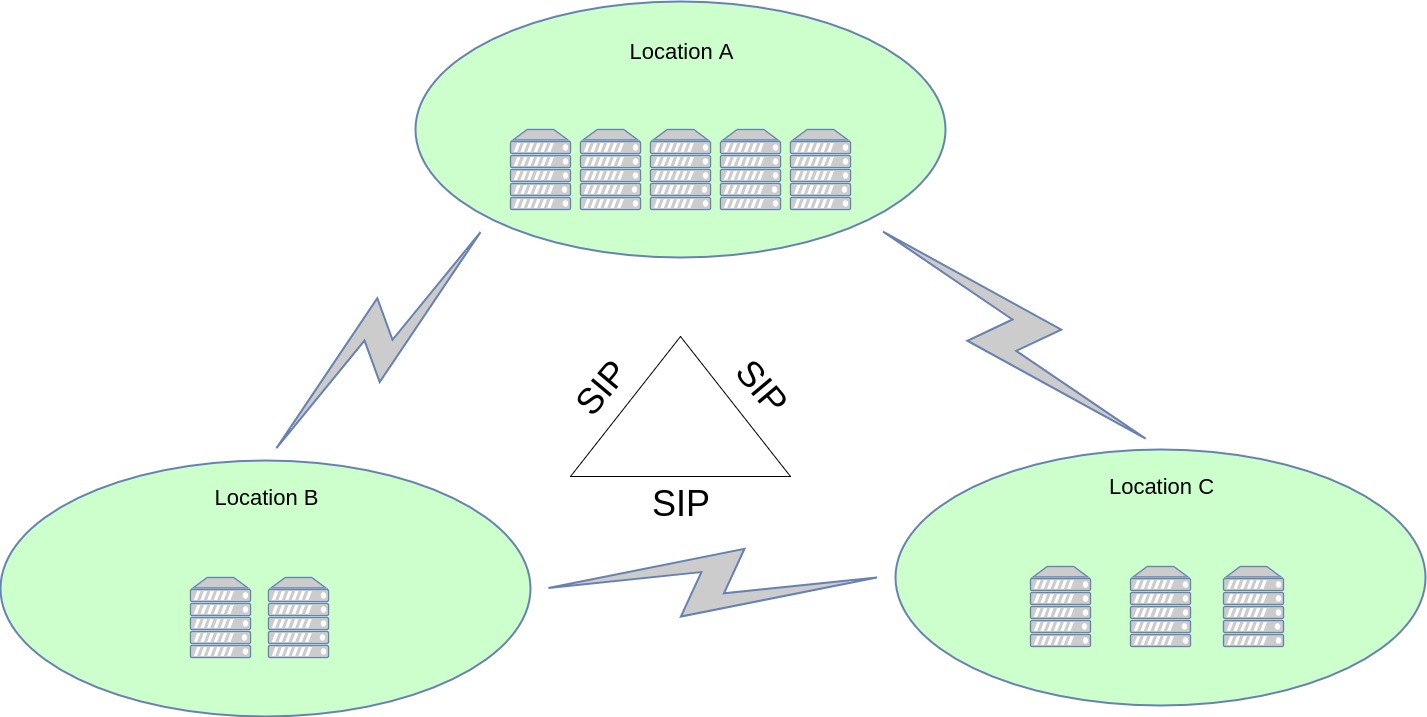
1.1 "SIP driven" user facing topology
This solution is ideal for SMBs or as a proof of concept. With the SIP driven solution, after saving an incoming registration, the registrar node records itself using a Path header, after which it replicates the REGISTER to all cluster nodes across all locations. This allows the user to be globally reachable, while also making sure it only receives calls through its "home box" (a mandatory NAT requirement in most cases). NAT pinging is only performed by the "home box".
PROs:
- possible with some OpenSIPS 2.X scripting
- can easily inspect/troubleshoot network traffic between locations
- built-in solution, no external database required
CONs:
- complex OpenSIPS script, since it handles the distribution logic, rather than masking it behind existing primitives (save(), lookup())
- each OpenSIPS node holds the global (across locations) user location dataset
- SIP replication is expensive (network and parsing overhead)
Development:
- [TODO 1][optional]: implement a script mechanism to simplify the forking of REGISTERs to all cluster nodes
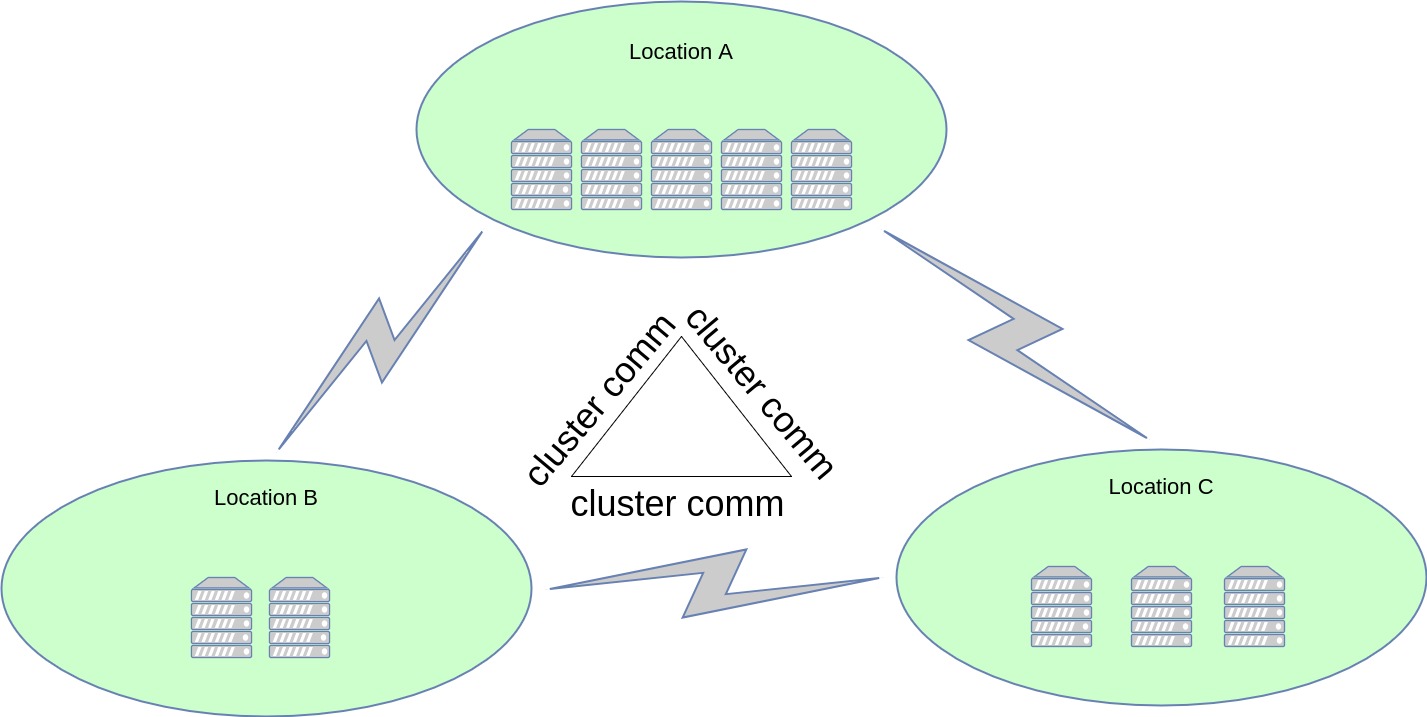
1.2 "Cluster driven" user facing topology
This solution is a heavily optimized version of the previous one, from three perspectives: performance, network link redundancy and scripting difficulty. Similar to the above, the end results, as seen from outside the platform, stay the same: global reachability, NAT traversal and pinging.
However, the difference is that we are now using the OpenSIPS clusterer layer for all inter-node communication. Immediately, this reduces the number of messages sent ("alice" is reachable here, rather than Alice's contact "deskphone" is now present here), the size of the messages (metadata only, rather than full-blown SIP) and the parsing overhead (binary data vs. SIP syntax). Furthermore, by using the cluster-based communication, the platform now becomes resilient to the loss of some of its cross-location data links. As long as the "platform graph" stays connected, the cluster-based distributed location service will remain unaffected.
PROs
- heavily optimized communication between nodes (number of messages / size of messages / parsing complexity)
- service can survive broken links between locations
- trivial OpenSIPS scripting (save() and lookup() almost stay the same)
- built-in solution, no external database required
CONs
- cluster comms packets are cumbersome to troubleshoot (submit Wireshark dissector?)
Development:
- [TODO 1]: Address-of-Record metadata replication, e.g. {"aor": "liviu", "dst_cluster_node_id": 1}
- [TODO 2]: enhance lookup() to support parallel forking across multiple locations (using metadata info)
- [TODO 3]: enhance save() to broadcast data throughout cluster
- [TODO 4]: solve "node restart" and "node down" corner-cases (broadcast "I am empty" packet, broadcast all my metadata to all cluster nodes)
- [TODO 5]: implement a "node sync" mechanism on startup
- [TODO 6]: "node self-recovery" MI command (re-use TODO 4 mechanism)
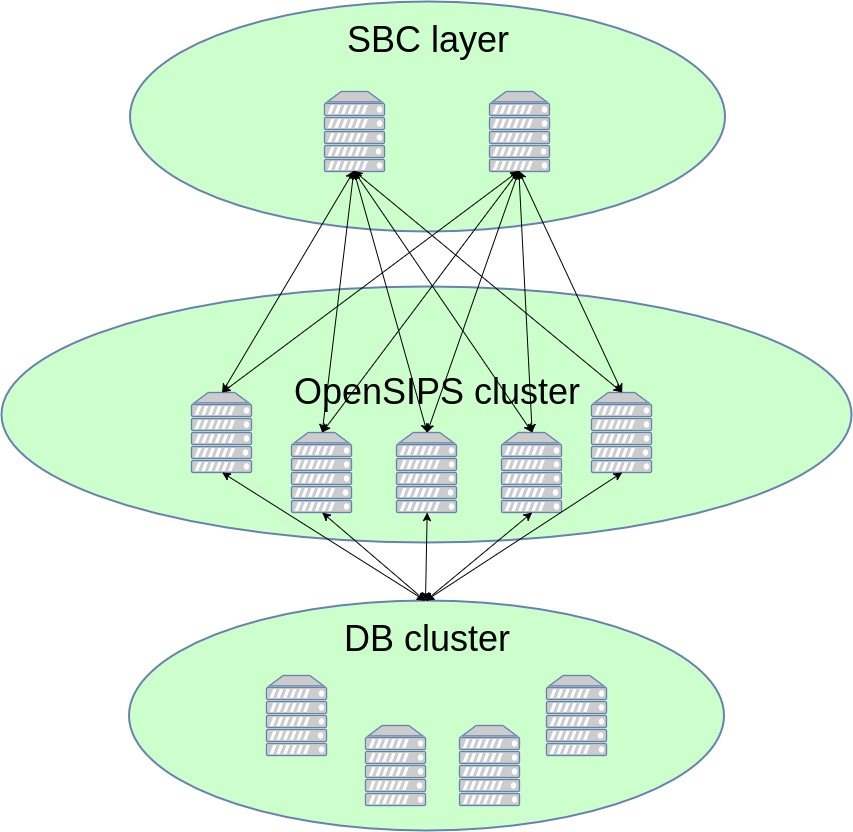
2. "Homogeneous cluster" topology
The homogeneous cluster solves the following problems:
- geographical distribution - the overall platform may span across several physical locations, with any of its users being reachable from any of these locations.
- NAT traversal - outgoing requests are directed through the SBC layer, which maintains the NAT bindings
- NAT pinging - no extraneous pinging; the cluster self-manages pinging responsibilities according to the current node count
- horizontal scalability - the service may be scaled up or down by dynamically adding/removing OpenSIPS cluster nodes
- high availability - by default, as data is either duplicated on multiple OpenSIPS nodes, or in a manner pertaining to the chosen DB cluster engine
We present two solutions for achieving this setup: a "basic" solution and an "advanced" one.
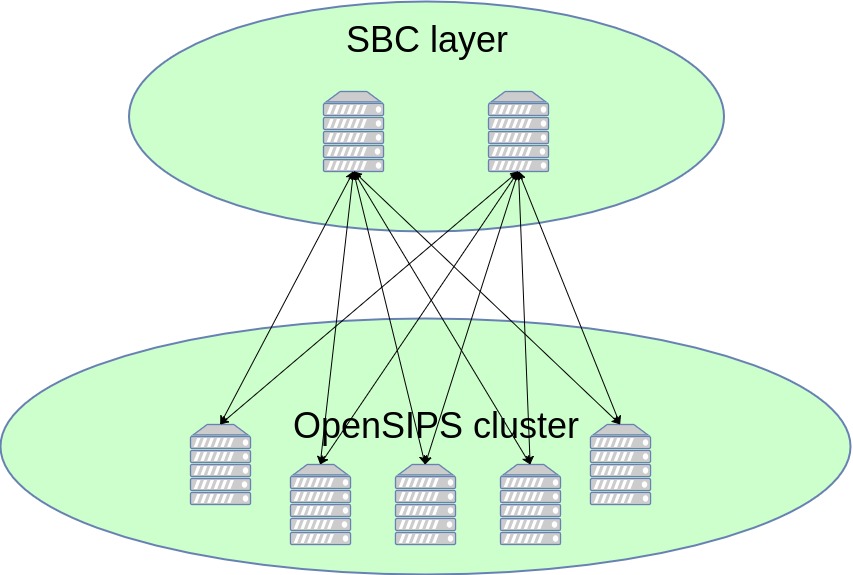
2.1 "Basic" OpenSIPS homogeneous cluster topology
This solution is an appropriate choice for a single site with a medium-sized subscriber population (order of millions), which could all fit into a single OpenSIPS box (all cluster boxes are mirrored). The NAT bindings are tied to the SBC layer, with the cluster nodes routing out both call and ping traffic through this layer. With the help of the cluster layer, which is able to signal when a node joins/leaves the network, each node is able to determine its very own "pinging slice", by performing an AOR hash modulo current_no_of_cluster_nodes.
PROs:
- node redundancy (each node holds a full dataset copy)
- easy to configure and scale up/down
- trivial OpenSIPS scripting
- no external database required
CONs:
- can only scale up to the maximum number of location contacts handled by a single instance
Development:
- [TODO 1]: implement "sync on startup" feature
- [TODO 2]: solve NAT pinging problem (in-memory filter)
2.2 "Advanced" OpenSIPS homogeneous cluster topology
This solution is to be employed by single sites with high population numbers (order of tens/hundreds of millions). At these magnitudes of data, we cannot rely on OpenSIPS to manage the user location data anymore (unless we kickstart "OpenSIPS DB") - we would rather pass this on to a specialized, cluster-oriented NoSQL database which offers data partitioning and redundancy.
Similar to the "basic" solution, the NAT bindings are tied to the SBC layer, with the cluster nodes routing out both call and ping traffic through this layer. With the help of the cluster layer, which is able to signal when a node joins/leaves the network, each node is able to determine its very own "pinging slice", by applying an AOR hash modulo current_no_of_cluster_nodes filter to the DB cluster query.
PROs:
- OpenSIPS node redundancy (any node is capable of saving / looking up contacts)
- easy to configure and scale up/down
- high-end solution, capable of accommodating large subscriber pools
- trivial OpenSIPS scripting
CONs:
- may not be compatible with too many NoSQL backends
Development:
- [TODO 1]: implement full usrloc data handling via CacheDB
- [TODO 2]: research all NoSQL backends capable of handling the usrloc data format requirements
- [TODO 3]: adapt the cacheDB API and expand its capability set to match the above
- [TODO 4]: solve NAT pinging problem (DB query filter)
- [TODO 5][optional]: assess performance and implement a "ping cache" if the read queries required by NAT pinging prove to be a bottleneck