About -> Performance Tests -> MySQL prepared statements
This page has been visited 37992 times.
Starting with OpenSIPS 1.5.0 the internal DB API provides support for prepared statements. First DB module to implement prepared statements is DB_MYSQL module. See more about the concept of prepared statements in MySQL.
The tests were conducted in order to determine the real gain of prepared statements. The tests tried to cover various case - combinations between complexity of a query and the amount of data transfered by a query.
A very good overview on Prepared Statements, that may help you in understating the advantages and disadvantages of prepared statements can be found at http://www.mysqlperformanceblog.com/2006/08/02/mysql-prepared-statements/ .
It is essential to understand that prepare statements do not bring only performance, but more security also!
1. What are the theoretical gains ?
Client side:
- save on building the string query
- save on converting to string all types of data provided by DB API
- no need for string / blob escaping
- eliminates the risk of SQL injections
- save memory for buffering strings, blobs, other data
Server side:
- save parsing the query each time
- no need to unescape data
2. Limitations ?
Query cache does not work for prepared statements, but considering that the OpenSIPS data is very large and various, it is not something to affect the performance (as the below results shows).
Prepared statements have a gain in speed only if used more than once - for this reason, only the queries which are repetitively used in OpenSIPS are converted to prepared statements ; initial load are still using standard queries.
3. Performance tests
The tests were done using OpenSIPS 1.4.4 as reference point for DB query performance without prepared statements. OpenSIPS 1.5.0 is the candidate measurements with prepared statements.
Notes:
- to simulate as much as possible a real world setup, were server query caching has no impact (due data volume), the mysql server that was used had the query cache disabled;
- OpenSIPS was located on the same machine with mysql server, in order to eliminate any network anomalies;
- SIPP was used to generate REGISTER traffic (scenario will be shortly uploaded); SIPP was locate on a different machine, to avoid any interferences with OpenSIPS
- what was measured was the response time at application level (at the level of modules using the DB API); so, the measured time includes the time to prepared the query, to send and wait the query from server and to fetch results.
- tests were composed of 10 000 measurements per test
3.1 DB Authentication test
This test (using auth_db module) was focus in measuring he gain of a simple query:
- low complexity query (as simple select with 2 fields)
- low volume of data pushed to mysql (2 short strings - username and domain)
Scenario: REGISTER requests, challenged and authenticated.
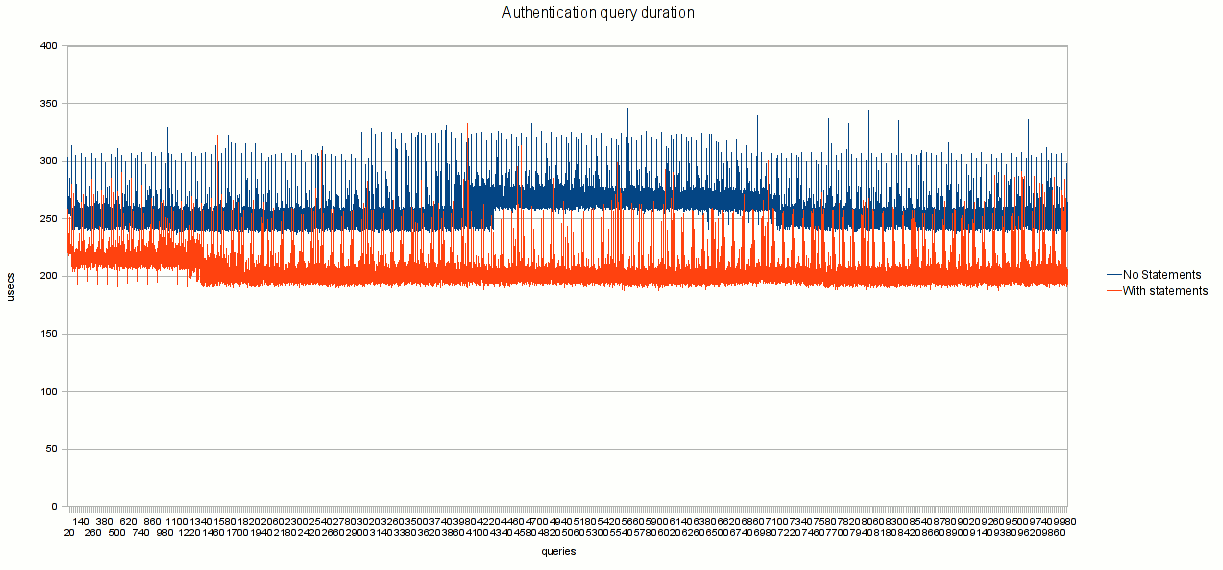
Chart 1
Results:
- no prepared statements (OpenSIPS 1.4.4) = 254 micro secs (avg per query)
- with prepared statements (OpenSIPS 1.5.0) = 202 micro secs (avg per query)
3.2 User location test
This test (using usrloc module) was focus in measuring he gain of more complex query:
- highy complexity query (an insert with 13 fields and 2 "where" values)
- low volume of data pushed to mysql (only short strings, integers, datatime values)
Scenario: REGISTER requests, no authentication,
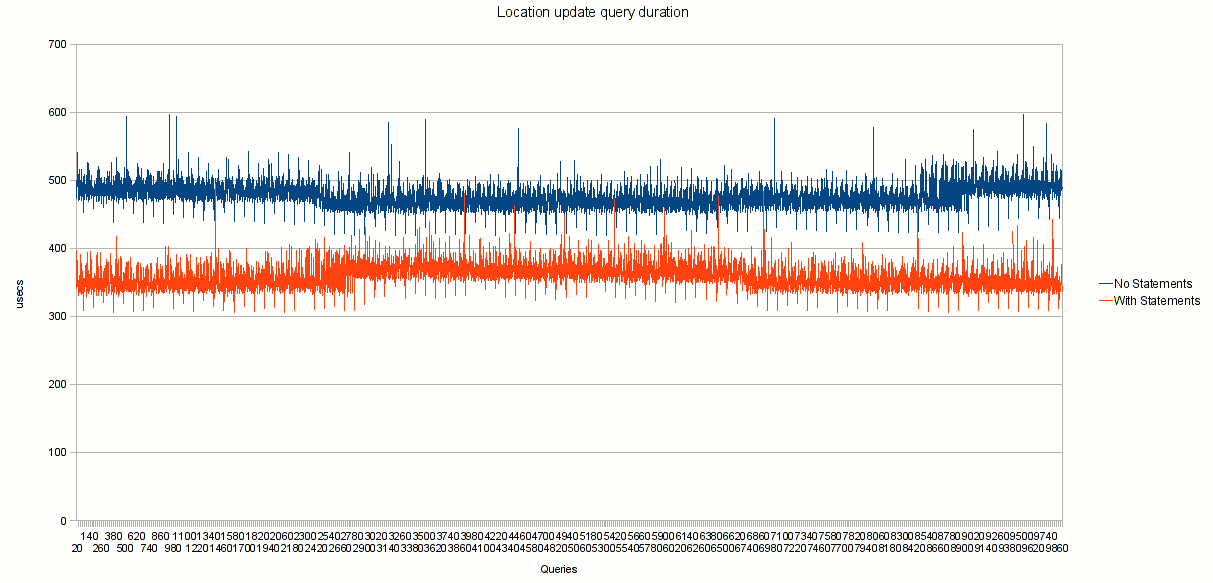
Chart 2
Results:
- no prepared statements (OpenSIPS 1.4.4) = 477 micro secs (avg per query)
- with prepared statements (OpenSIPS 1.5.0) = 358 micro secs (avg per query)
3.3 SIPTrace test
This test (using siptrace module) was focus in measuring he gain of simple, but datafull query:
- low complexity query (an insert with 6 fields)
- large volume of data pushed to mysql (BLOBs containing a whole SIP message is inserted)
Scenario: REGISTER requests, no authentication,
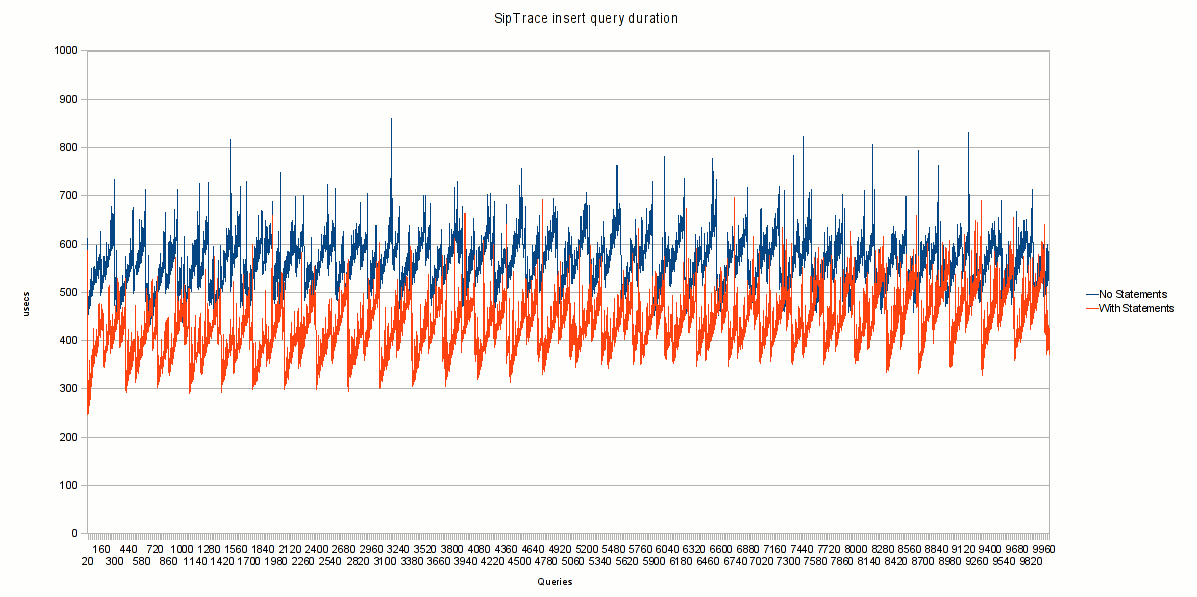
Chart 3
Results:
- no prepared statements (OpenSIPS 1.4.4) = 556 micro secs (avg per query)
- with prepared statements (OpenSIPS 1.5.0) = 428 micro secs (avg per query)
Technically, CSV should wrap fidles that contain a comma in simple double quotes. That should take care of situations like that. The only complication is when you have a text field with double quotes inside them. Although scripts that read in CSVs should again, according to the presumptive standard of RFC 4180 -pay close attention so as to only recognize as delimer , the reality is many importing scripts just grab the first double quote they see and run with it as a delimiter. That's why I like TSVs; tab-separated text files, with the .txt extension and not .csv so as to avoid MS Excel reading problems with UTF-8 and multi-byte characters (when you open or import a .txt file in Excel it'll accept non-ASCII / ANSI files and read them as such). And with the combo quote-tab-quote the chance of picking on a field with that combo in it are rather slim, much more so than the quote-comma-quote sequence.If you're interested at all, there's currently a decent . You'll see it's very complicated from a programmer's POV (e.g. the intelligent placement of quotes). I suppose the quick solution is to just plop quotes around every field, i.e. not just the first or header row. I've also suggested the good people at YM to consider adding TSV but I'm not optimistic about support for that @#$% serialized usermeta crud.My kingdom for a usermeta cleaner!