|
Development |
Development -> New Design -> DescriptionThis page has been visited 39564 times. Table of Content (hide) 1. Why a new designThe current (pre 2.x) OpenSIPS internal design is based on some concepts older than 7 years. At the time, the requirements were few (simple stateless UDP proxy) and the decisions were made accordingly. But with all the additions, both in SIP and functionality (like TCP/TLS, script manipulation, dialog support, external integration, etc), the existing design is not able to cope with the requirements and use-cases any more. The issues that the new design tries to solve are:
2. New design overviewTaking into considerations all the existing issues with the current design, the good parts of the existing design and also the direction SIP and OpenSIPS are moving towards, a new model was designed. At the highest level, OpenSIPS will be structured into 2 completely separate conceptual parts:
By design, one or multiple Routing Engines can hook to a single Core in order to either implement different functionalities, or to simply increase the processing power of the whole system. 3. SIP CoreThe Core will be the low-level part responsible for providing SIP-related functionalities that can be performed automatically and do not require a complex configuration. In brief, the Core will handle transport, parsing, transactions and dialogs as well as all the automated processing related to NAT traversal, SIP registration and presence, functionalities that are well defined by the RFC and do not require any intervention from the high level Routing Engine in order to be executed. The Core is structured as multiple horizontal layers, each layer performing a well defined function:
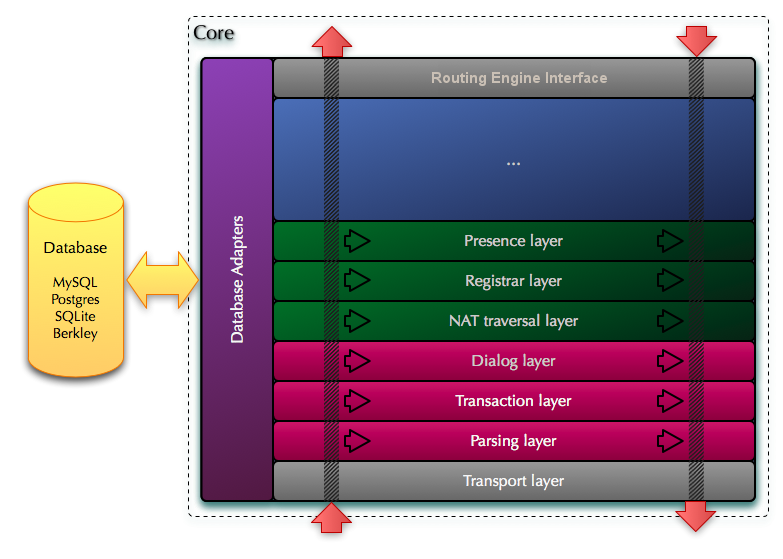 Core structure (detail) The SIP message will enter at the lowest layer L0 and each layer will process the message and the either push it up to the next layer or return it to the layer below if such a condition occurred that dictates that the message processing stops there (like for example automatically replying to a keepalive message or handling a retransmission). When it reaches the layer that provides communication with the Routing Engine, the message is pushed the same way (with all the modifications that were performed by each layer up to this point) into the Routing Engine, which will continue to further process the message and make a decision before returning it over a reverse path that goes top-down from layer to layer until it reaches the transport layer (L0) and is sent out. The Core has 2 flows for the messages it processes:
During both flows, each layer may perform different actions (like SIP parser layer will parse messages for the inbound flow and it will also assemble back messages on the outbound flow). SIP messages will be read from the network by L0 (the transport layer) and they will be pushed from bottom up through the upper layers. Each layer will perform its corresponding action (like the SIP parser layer will attach to the message context the parsed form, the Transaction layer will attach a transaction ID, the dialog layer will attach a dialog ID, etc). After performing its task, a layer may have the following options: (a) push the message context to the following upper layers for processing (if current layer could not complete the processing) or (b) can take the decision what to do with the message and will push it in the outbound flow for sending out (in this case, all the upper layers will be skipped). This behaviour will allow a certain layer to automatically deal with certain messages with maximum efficiency: there is not need to propagate all the messages through all layers and up to the Routing Engine if the message can be handled automatically by a certain layer. One example is replying to a keepalive message that can be dealt automatically in the Core's NAT traversal layer. Another example is when the Routing Engine is only interested in receiving and processing the initial requests alone. In such a case, the sequential requests will be automatically processed and routed by the Dialog layer without any need to push them further up in the chain of processing. In addition to the layers, the Core will also implement several database backends, which are required to provide persistence over restarts for the internal data that each layer in the Core needs to store in memory (dialog, presence, registrar and nat traversal information). Inside the Core, we can also make a distinction among layers based on their importance:
The Core will have its own configuration file in order to provide options for the core layers and thje database backends: listening interfaces, TM options, dialog settings, etc... The Core will be implemented around an asynchronous reactor in order to handle non-blocking I/O. For efficiently using all the CPU resources on machines with multiple CPU cores, the Core will use multiple threads (as many as CPU cores). 4. Routing EngineThe Routing Engine will implement the equivalent of the existing routing script and also provide the functionality of most of the currently existing modules. The Routing Engine will run on top of the Core as a separate entity. As mentioned before, more than one Routing Engine can be connected at the same time to a given Core, either to provide different services or to increase the processing capabilities of the system by distributing the load on multiple machines. The new design will allow two approaches when it comes to assembling the Core with the Routing Engine:
Why two approaches? the two options do not overlap, but rather complement on each other - the internal Routing Engine will be more efficient when comes to performance and controllability (due tight and natural integration to the Core directly at C level), while the external Routing Engine will be much more versatile and simpler to implement (being a standalone application in a high level language), much simpler to control (being a separate application). 4.1 Internal Routing EngineThe Routing Engine will be a set of extra layers, provided as a library, that will be linked together with the Core component, creating a single application. The Routing Engine will include:
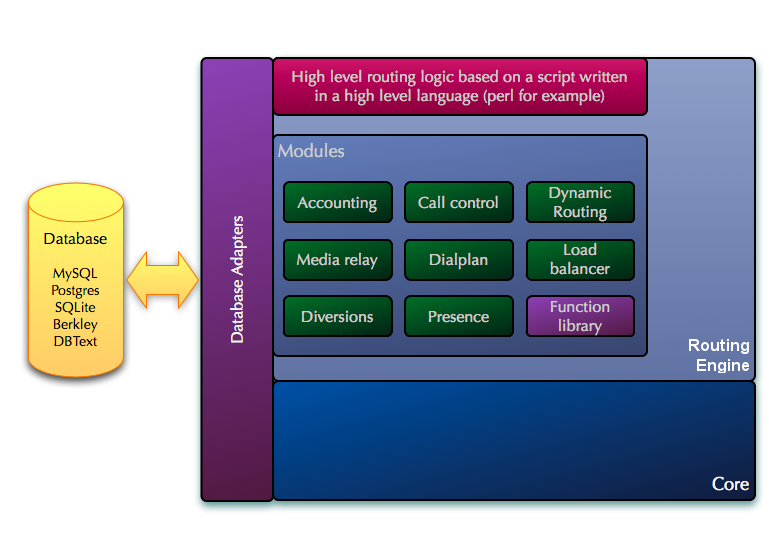 Internal Routing Engine (detail) The script interpretor will be based on the existing custom scripting language with the possibility to directly embed script chunks of a high level language (like embedding Perl code). Depending on the performance penalties, completely replacing the custom scripting with a high level language will be an option (like having the whole Routing Engine written in Perl and triggering C functions from the modules or Core). The existing native script is still a choice that can be provided in the new design as well, because the interpretor is very fast and it is perfectly suited for configurations with a very simple logic driving a high load. The high-level script embedding is still an useful choice as it will dramatically simplify scripting where a complex routing logic is required, given the complex data processing abilities of the high level language. In addition to reducing the effort to write complex scripts it will also eliminate the need to learn the limited native scripting language. But some penalty to performance will occur in this case, as the interpreters for high-level languages are heavier and slower. On the other side, a high level language will allow to achieve horizontal scaling - imagine a cluster of OpenSIPS (on multiple servers) where all the Routing Engines (using language specific functionalities or storage engines) are networked together behaving as a single entity - a single global Routing Engine using multiple OpenSIPS Cores. The modules from the Routing Engine layers will provide pre-defined fuctionalities (dialplan, lcr, qos, b2bua, etc) which can be used from the script, irrespective of the script format. The possibility to re-load the script at runtime will be available. 4.2 External Routing EngineAs with the Core, the external Routing Engine (or application) will also be implemented as a set of layers that pass the messages between them in 2 directions (bottom-up and top-down). These layers culminate with the high level routing logic layer, which is the part that is implemented by the user and provides the custom routing logic that is specific to one's SIP service. This last layer is equivalent with the script that contains the Routing Engine in the old design. Some of the layers are active, meaning that they will modify the message in transit and may even make decisions to stop relaying the message up, finalize its processing and return it downwards, based either on the message content or a previous instruction from the top level routing logic layer. Some other layers are however passive. They will only provide classes and functions that implement a certain functionality (like say LCR or call control) and they will not be passed-through by the message in its way up, instead they will only perform changes on the message if called explicitly by the user from the top routing logic layer. 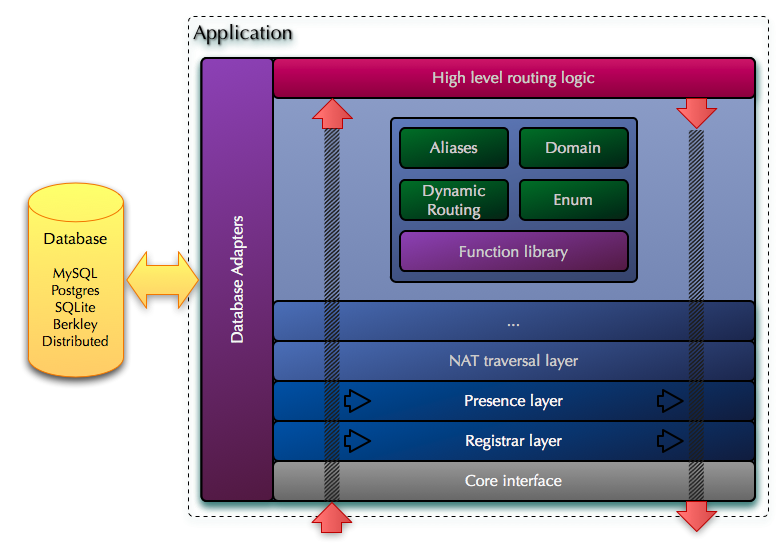 Application (detail) The application will register with a given Core (or with multiple Cores if desired) and will announce its capabilities to the Core. These include what messages it is interested in processing and its processing limits. These allow a Core to filter what messages and how many to send to a given application. In addition the application can instruct the Core to dynamically enable/disable certain of the optional layers in the Core when the Core finds a message that it has to be forwarded to this particular application. This allows for very flexible configurations where an certain application can for example instruct the Core that for all the messages forwarded to that particular application, to disable the NAT traversal layer in the Core. As a result when the Core forwards a message to this particular application it will skip the NAT traversal layer, which means that the application wishes to deal with the NAT traversal itself. It also means that the application will receive the keepalive messages. Other applications however if they do not disable this layer, they will not see keepalive messages, nor will they need to deal with NAT traversal themselves, because in their case the NAT traversal layer will be active and used. This allows for a very flexible setup where certain optional parts of the Core can be enabled/disabled at runtime without any need to change the Core configuration or to restart the Core. 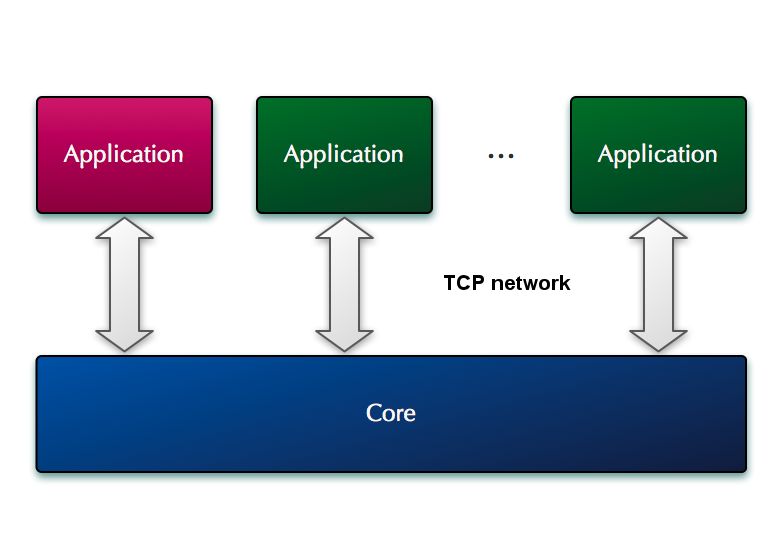 Multiple Applications with a single Core The whole application will be written in a high level language like python. The implementation in OpenSIPS will provide all the required functionality and support that will allow a user to write the high level routing logic. This corresponds to the last layer in the application diagram. This will look very much like the existing script, only it will be written in the same language (python in this case) as the rest of the application. Of course, the application can be implemented in other languages as well like java, ruby or perl. |
Page last modified on October 10, 2014, at 03:17 PM